 Data Science Ethics Summer 2023
Data Science Ethics Summer 2023Data Science Lifecycle
A Data Science Lifecycle or Pipeline: a diagram that depicts a relationship between different stages of data science (e.g., data collection, data cleaning, model-building).
Though it might not be explicit, using one lifecycle or pipeline over another endorses specific views about data, data models, and their respective relationships to what we take to be knowledge about our world. Thus, the choice to use a certain data science lifecycle is value-laden.
Here, I examine two popular conceptions of the relationships between data, data models, and what we should interpret as knowledge about our world (i.e., the epistemic roles of data and data models) (Leonelli, 2018):
The representational view of data and data models
The relational view of data and data models
Data Models: “arrangements of data that are evaluated,
manipulated and modified with the explicit goal of representing a
phenomenon, which is often (though not always) meant to capture specific
aspects of the world,” (Leonelli, 2018).
Examples
of Data Models:
1. A simple linear regression that uses
years of education to model the expected income is a data
model.
2. An algorithm that utilizes millions of hyperparameters
to predict an incarcerated individual’s risk of recidivism.
3. A
data visualization that describes a relationship between variables
within a sample.
In the following two subsections, I provide an explication of the representational and relational view of data and data models and some benefits of using the relational view of data and data models over the representational one. I recommend reading Leonelli (2018) for a more in-depth justification of the value of a relational view of data and data models over a representational one.
The Representational View
Under the representational view of data and data models, the informational content of data is fixed and independent of the researchers’ background assumptions and context. Thus, data models are important only insofar as they extract the truth from the data. Hence, under the representational view, models are either objectively correct or incorrect, depending on their ability to elucidate the truth stored in the data. In other words, data models are only relevant because they clarify the arrows between data and knowledge in the diagram below (Leonelli, 2018).
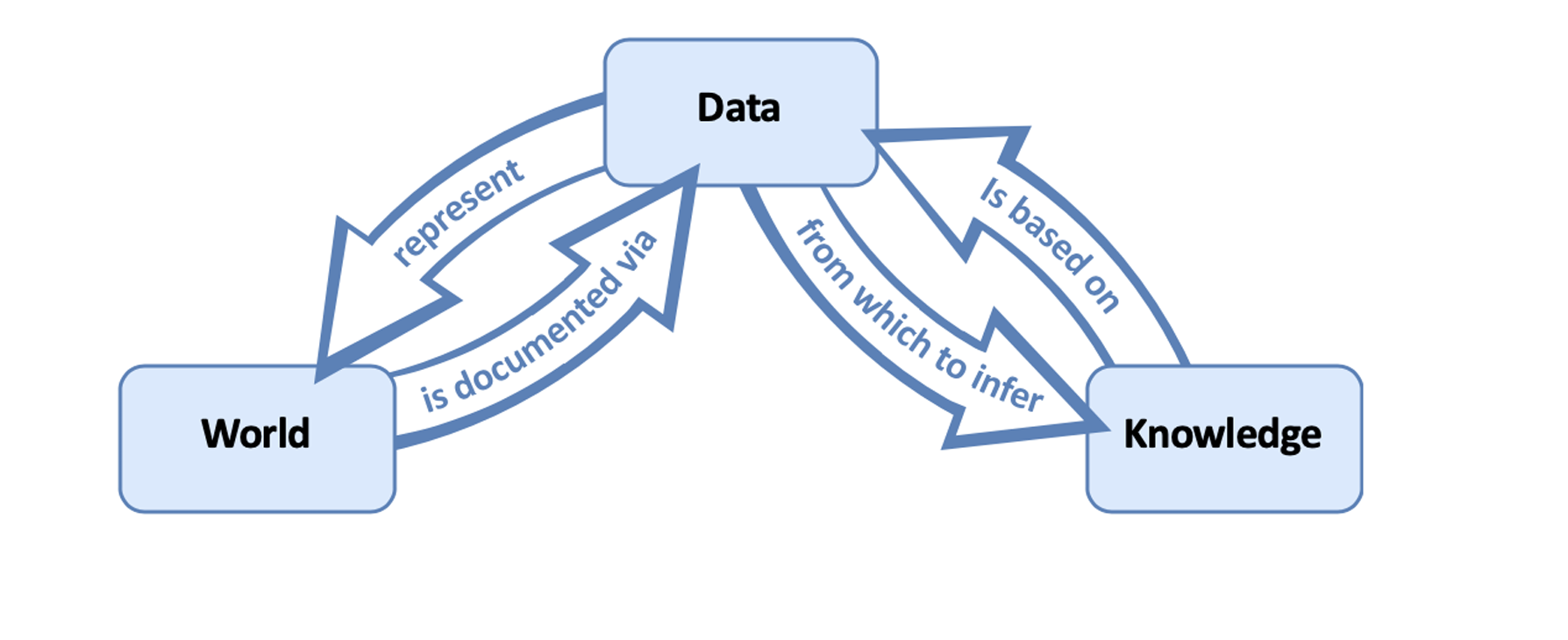
Data Science Lifecycle under the Representational View of Data and Models described by Sabina Leonelli in 2019. Any processing of the data, data organizing, or data modeling would merely be a tool to elucidate the connection between Data and Knowledge and the World.
The Relational View
Meanwhile, under the relational view of data and data models, data is understood as any object treated as evidence for at least one claim about the world and “is possible to circulate…among individuals/groups,” (Leonelli, 2018). Consequently, the informational content of data depends on the researchers’ background assumptions and social context. So, truth is not stored in data and is instead defined by its social environment and the function it is supposed to serve. As such, data models, not data, serve as representations of our world, making data models necessary and highly influential to knowledge production under the relational view of data and data models (Leonelli, 2018).
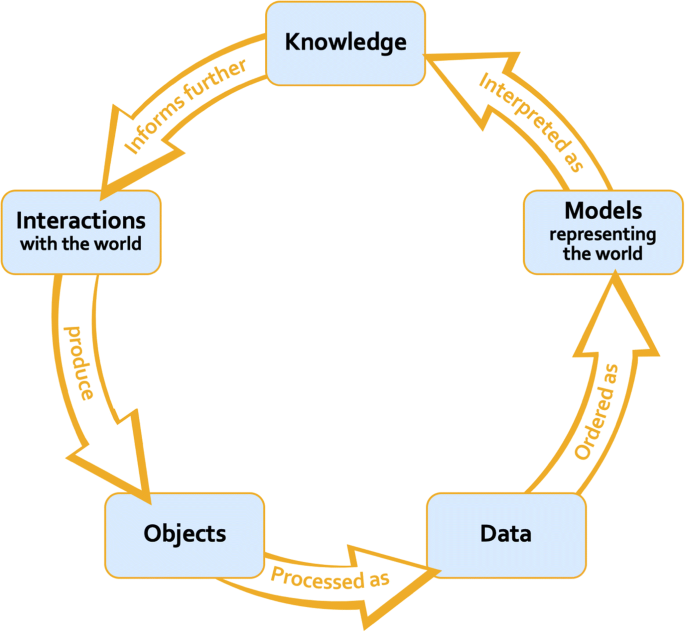
Data Science Lifecycle under the Relational View of Data and Models conceptualized by Sabina Leonelli in 2019.
The Relational vs. Representational View In-Practice
Consider how soccer match data influences our valuation of the match’s players (i.e., the phenomenon we are interested in understanding).
From the representational view of data and data models: the data inherently represents the actual soccer matches and players’ values. As such, questions about the data are solely focused on whether it is good enough. For instance, we may wonder if the sensors on the pitch are calibrated correctly.
Meanwhile, from the relational view of data and data models: data is only evidence in virtue of how it is organized. In turn, we would question why specific data should be evidence of a player’s value and how the larger social environment influences what data is generated. For instance, we may ask if data about the percentage of passes completed or kilometers run is better evidence of a soccer player’s value given our data model or how social contexts, like the role of FIFA videogames or social media, influence perceptions of soccer and data generation (Beaulieu & Leonelli, 2021, p. 59).
Such an example shows data in itself is representationally ambiguous and is dependent on its broader social environment. For instance, it is unclear what the sensors should be calibrated for, especially if calibration for foot speed reduces calibration for ball location, et cetera. There are many other questions that the representational view of data and data models neglects, such as which data model should be used and which variables (i.e., components of data) should be used within a given data model. Researchers must rely upon their background assumptions, knowledge, value judgments, and social contexts to answer these questions and, thus, what data is taken as evidence.
Therefore, this case study gives us reason to reject the representational view of data and data models in favor of the relational view of data and data models.
Silberzahn et al.’s “Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results”
In Silberzahn et al. (2017), 29 data analysis teams were asked to use the same data set to determine “whether soccer referees are more likely to give red cards to dark-skin-toned players than light-skin-toned players,”. Despite operating from the same data set, the final conclusions were split: 20 teams found that there was a statistically significant positive relationship, and 9 teams did not find a significant association between skin tone and the likelihood of the referee giving a red card.
The difference in chosen data model type and the relative importance of the potential predictor variables contributed to the division in the teams’ final decisions:
4 different model types were used: 15 teams used logistic models, 6 teams used Poisson models, 6 teams used linear models, and 2 teams used other types of models.
21/29 teams used unique combinations of predictor variables.
Through Silberzahn et al. (2017), we can also see how ambiguity about the data model and the relative importance of certain predictor variables also impacts what data is taken as evidence. No two teams had the same set of evidence for their claim about the relationship between skin tone and the likelihood of the referee giving a red card. As emphasized by Silberzahn et al. (2017), each team’s evidence set was defensible based on the original data set provided. Yet, these evidence sets were also subjective in the sense that they relied upon the analysts’ background assumptions, value judgments, knowledge, and social contexts.
Hence, Silberzahn et al. (2017) emphasize that data and data models should be viewed relationally rather than representationally.
The Final Data Science Lifecycle
Several lifecycles are compatible with a relational view of data. The final data science lifecycle I will use on this website endorses the relational view of data and data models proposed by Leonelli (2018). The diagram below shows us where paradigmatic data science practices occur in the selected lifecycle (Beaulieu & Leonelli, 2021, p. 58).
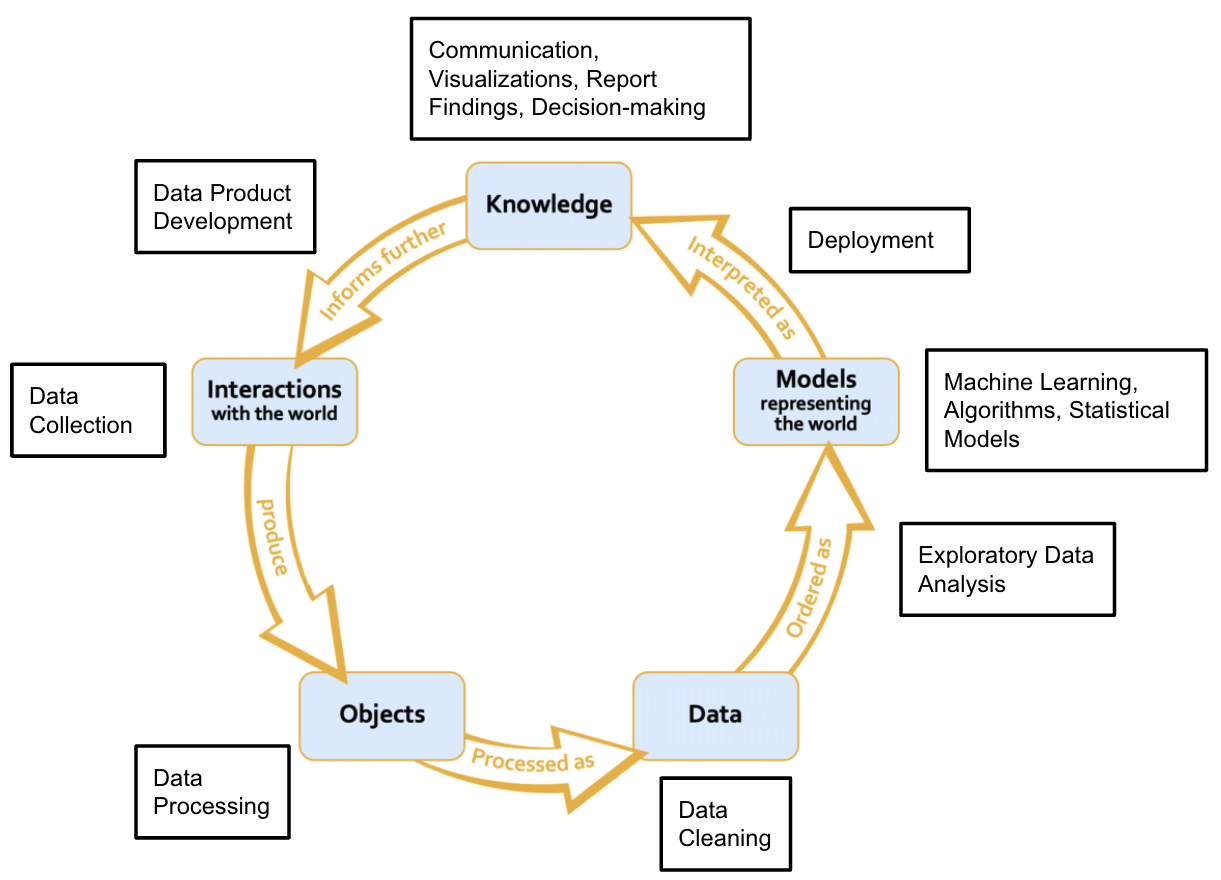
Data Science Lifecycle under the Relational View of Data and Models Superimposed with Paradigmatic Data Science Practices (Beaulieu & Leonelli, 2021, p. 58).